Talk recordings
The Springer proceedings of KI 2020 are already available online.
Keynotes

To operate effectively, and to collaborate with humans, robots need to know much about the world, including the kinds of objects in the world, their properties, the spatial relationships between them and actions that can be performed on them, as well as how language is used to describe these things. I will present a cognitively plausible novel framework capable of /incrementally/ learning a language used to give commands to a robot in a table top environment, and the grounding of linguistic concepts to the induced visual semantics of the observed scenes. The system also induces a set of probabilistic grammar rules governing the previously unknown language. I also plan to talk about new work in which we show how robots can improve their manipulation planning in cluttered environments by learning from human demonstrations in virtual worlds.

One of the main obstacles for developing flexible AI systems is the split between data-based learners and model-based solvers. Solvers such as classical planners are very flexible and can deal with a variety of problem instances and goals but require first-order symbolic models. Data-based learners, on the other hand, are robust but do not produce such representations. In the talk, I look at recent work in my lab aimed at bridging this gap by learning first-order symbolic representations for planning and for generalized planning directly from non-symbolic data.

Search algorithms are among the core techniques of Artificial Intelligence. Continuous research over seven decades has led to breakthroughs, which are at the heart of contemporary learners and solvers, where search helps to trains neural networks, play games, or solve complex combinatorial optimization problems. In this talk, I review the state of the art in search algorithms. I discuss the potential and selected open research problems and illustrate them with examples from practical applications where search is used to solve industrial planning and scheduling problems.

Relational Learning (RL) and Relational Data Mining (RDM) address the task of inducing models or patterns from multi-relational data. One of the established approaches to RDM is propositionalization, characterized by transforming a relational database into a single-table representation. The talk provides an overview of propositionalization algorithms, and a particular approach named wordification, all of which have been made publicly available through the web-based ClowdFlows data mining platform. The focus of this talk is on recent advances in Semantic Relational Learning and Semantic Data Mining (SDM), characterized by exploiting relational background knowledge in the form of domain ontologies in the process of model and pattern construction. The open source SDM approaches, available through the ClowdFlows platform, enable software reuse and experiment replication. The talk concludes by presenting the recent developments, which allow to speed up SDM by data mining and network analysis approaches.

One of the fundamental problems in AI is to enable computational agents to access human knowledge expressed in natural language. For decades this meant teaching machines to “read text” by turning it into highly structured knowledge bases ready for downstream use. In this talk I will discuss two recent alternative paradigms at seemingly opposite ends of a spectrum. In retrieve-and-read approaches text is left as is, and is retrieved and comprehended on as-needed basis, much in the way open book exams work. In recent closed book approaches, all knowledge has been stored in the parameters of massive language models without the need for retaining text corpora at all. I will contrast the strengths and weaknesses of both approaches, and show how we overcome some of them in our most recent works, partly by finding synergies between the two.

The success in the field of machine learning and in particular the aspects of representation learning, and deep nets have not only a significant impact in the academic world, but also show their added value in within corporate world and its industrial applications. From visual quality inspection, dynamic price determination, autonomous parameter optimization, improved adaptivity of robotics controls and AI-optimized supply chains to predictive maintenance in production. Algorithms make our lives more efficient, increasingly support our (often human gut feeling-driven) decision-making process, and in part they take it over. The strength and at the same time the challenge aspect of modern ML, is when they hit the beautiful real world of imperfection and uncertainty, that is coping with new situations and unknow unknows. As the quality of performance strongly depends on the size, balance and purity of the input data, which is rarely given in terms of quantity and quality, new approaches towards self-supervision and trustworthiness are of importance. This talk motivates some research challenges within real-world applications of Industrial AI and present recent research work from the lab on robustness, explainability, and continuous learning for industrial applications.
Panel

- Kick-off presentations
-
-
Activities of the special interest group concerning AI education
-
Highlights of results of the empirical study concerning AI knowledge
-
Activities of the special interest group concerning AI education
- Discussion
-
Search, Optimization, Machine Learning

In this paper, we combine the theory of probability aggregation with the theory of meta-induction and show that this allows for optimal predictions under expert advice.
The full paper to this contribution is published as:
Feldbacher-Escamilla, C.J., Schurz, G.: Optimal probability aggregation based on generalized brier scoring. Ann. Math. Artif. Intell. 88(7), 717–734 (2019).
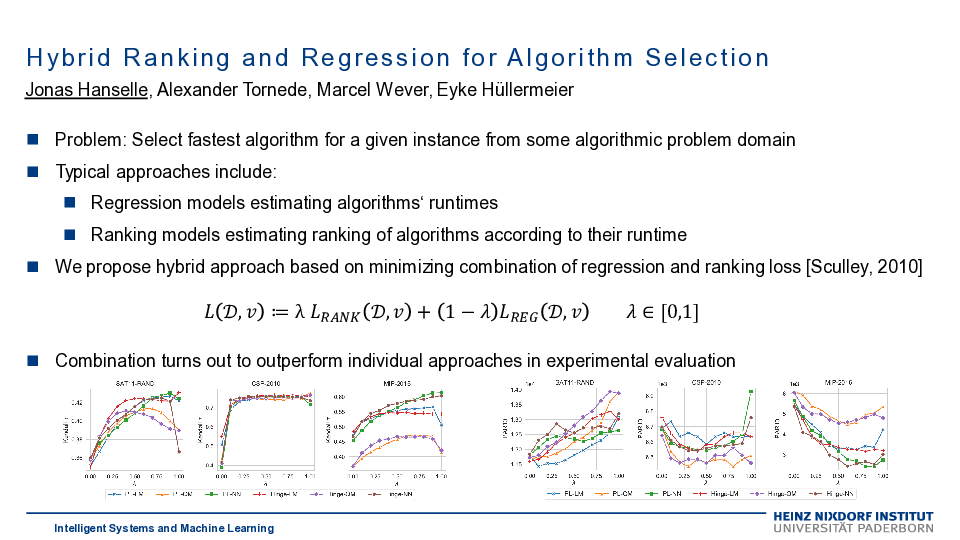
Algorithm selection (AS) is defined as the task of automatically selecting the most suitable algorithm from a set of candidate algorithms for a specific instance of an algorithmic problem class. While suitability may refer to different criteria, runtime is of specific practical relevance. Leveraging empirical runtime information as training data, the AS problem is commonly tackled by fitting a regression function, which can then be used to estimate the candidate algorithms’ runtimes for new problem instances. In this paper, we develop a new approach to algorithm selection that combines regression with ranking, also known as learning to rank, a problem that has recently been studied in the realm of preference learning. Since only the ranking of the algorithms is eventually needed for the purpose of selection, the precise numerical estimation of runtimes appears to be a dispensable and unnecessarily difficult problem. However, discarding the numerical runtime information completely seems to be a bad idea, as we hide potentially useful information about the algorithms’ performance margins from the learner. Extensive experimental studies confirm the potential of our hybrid approach, showing that it often performs better than pure regression and pure ranking methods.
https://link.springer.com/chapter/10.1007/978-3-030-58285-2_5

In this paper we look at multi-player trick-taking card games that rely on obeying suits, which include Bridge, Hearts, Tarot, Skat, and many more. We propose mini-game solving in the suit factors of the game, and exemplify its application as a single-dummy or double-dummy analysis tool that restricts game play to either trump or non-trump suit cards. Such factored solvers are applicable to improve card selections of the declarer and the opponents, mainly in the middle game, and can be adjusted for optimizing the number of points or tricks to be made. While on the first glance projecting the game to one suit is an over-simplification, the partitioning approach into suit factors is a flexible and strong weapon, as it solves apparent problems arising in the phase transition of accessing static table information to dynamic play. Experimental results show that by using mini-game play, the strength of trick-taking Skat AIs can be improved.
https://link.springer.com/chapter/10.1007/978-3-030-58285-2_2

Many problems from industrial applications and AI can be encoded as Maximum Satisfiability (MaxSAT). Often, it is more desirable to produce practicable results in very short time compared to optimal solutions after an arbitrary long computation time. In this paper, we propose Stable Resolving (SR), a novel randomized local search heuristic for MaxSAT with that aim. SR works for both weighted and unweighted instances. Starting from a feasible initial solution, the algorithm repeatedly performs the three steps of perturbation, improvements and solution checking. In the perturbation, the search space is explored at the cost of possibly worsening the current solution. The local improvements work by repeatedly flipping signs of variables in over-satisfied clauses. Finally, the algorithm performs a solution checking in a simulated annealing fashion. We compare our approach to state-of-the-art MaxSAT solvers and show by numerical experiments on benchmark instances from the annual MaxSAT competition that SR performs comparable on average and is even the best solver for particular problem instances.
https://link.springer.com/chapter/10.1007/978-3-030-58285-2_12
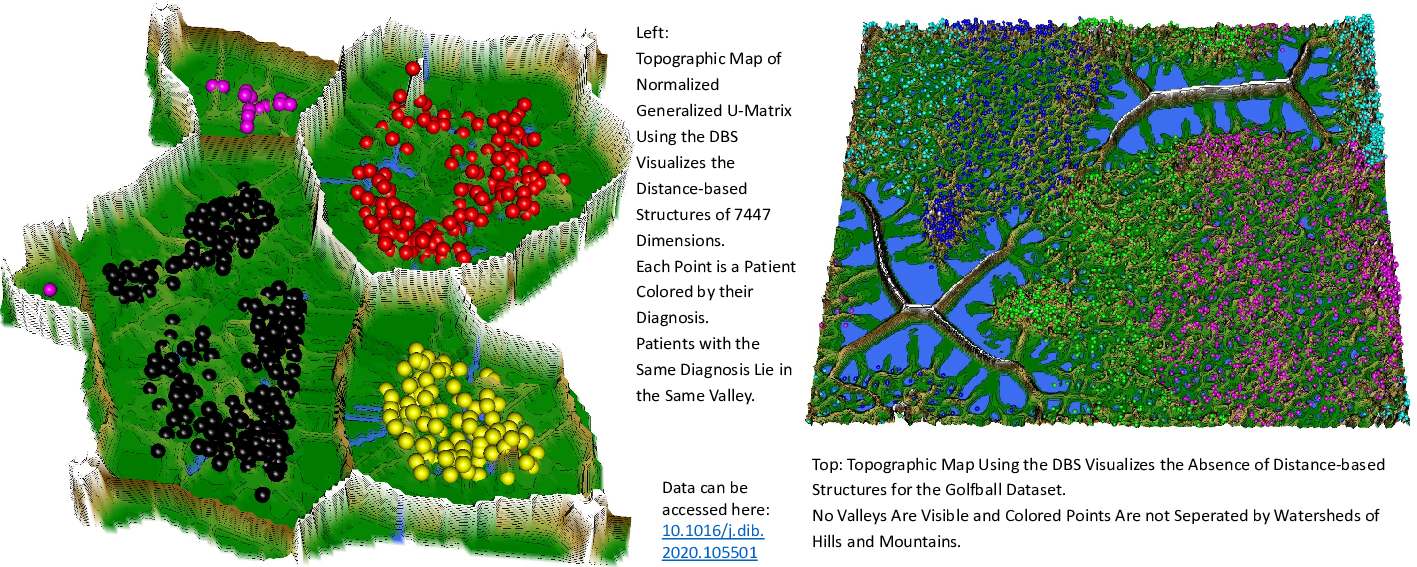
The Databionic swarm (DBS) is a flexible and robust clustering framework that consists of three independent modules: swarm-based projection, high-dimensional data visualization, and representation guided clustering. The first module is the parameter-free projection method Pswarm, which exploits concepts of self-organization and emergence, game theory, and swarm intelligence. The second module is a parameter-free high-dimensional data visualization technique called topographic map. It uses the generalized U-matrix, which enables to estimate first, if any cluster tendency exists and second, the estimation of the number of clusters. The third module offers a clustering method that can be verified by the visualization and vice versa. Benchmarking w.r.t. conventional algorithms demonstrated that DBS can outperform them. Several applications showed that cluster structures provided by DBS are meaningful.
This article is an abstract of Thrun, M.C., Ultsch, A.: Swarm intelligence for self-organized clustering. Artif. Intell. (2020).
https://link.springer.com/chapter/10.1007/978-3-030-58285-2_18

Multi-agent path finding with continuous movements and time (denoted MAPFR) is addressed. The task is to navigate agents that move smoothly between predefined positions to their individual goals so that they do not collide. Recently a novel solving approach for obtaining makespan optimal solutions called SMT-CBSR based on satisfiability modulo theories (SMT) has been introduced. We extend the approach further towards the sum-of-costs objective which is a more challenging case in the yes/no SMT environment due to more complex calculation of the objective. The new algorithm combines collision resolution known from conflict-based search (CBS) with previous generation of incomplete SAT encodings on top of a novel scheme for selecting decision variables in a potentially uncountable search space. We experimentally compare SMT-CBSR and previous CCBS (continuous conflict-based search) algorithm for MAPFR.
https://link.springer.com/chapter/10.1007/978-3-030-58285-2_16
Best Paper Session

We consider a fair division model in which agents have positive, zero and negative utilities for items. For this model, we analyse one existing fairness property (EFX) and three new and related properties (EFX0, EFX3 and EF13) in combination with Pareto-optimality. With general utilities, we give a modified version of an existing algorithm for computing an EF13 allocation. With −α/0/α utilities, this algorithm returns an EFX3 and PO allocation. With absolute identical utilities, we give a new algorithm for an EFX and PO allocation. With −α/0/β utilities, this algorithm also returns such an allocation. We report some new impossibility results as well.
https://link.springer.com/chapter/10.1007/978-3-030-58285-2_1

Current supervised learning models cannot generalize well across domain boundaries, which is a known problem in many applications, such as robotics or visual classification. Domain adaptation methods are used to improve these generalization properties. However, these techniques suffer either from being restricted to a particular task, such as visual adaptation, require a lot of computational time and data, which is not always guaranteed, have complex parameterization, or expensive optimization procedures. In this work, we present an approach that requires only a well-chosen snapshot of data to find a single domain invariant subspace. The subspace is calculated in closed form and overrides domain structures, which makes it fast and stable in parameterization. By employing low-rank techniques, we emphasize on descriptive characteristics of data. The presented idea is evaluated on various domain adaptation tasks such as text and image classification against state of the art domain adaptation approaches and achieves remarkable performance across all tasks.
https://link.springer.com/chapter/10.1007/978-3-030-58285-2_10
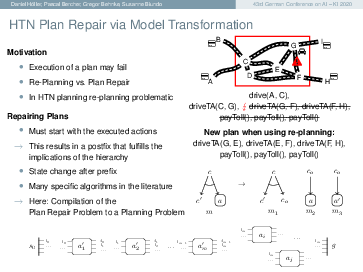
To make planning feasible, planning models abstract from many details of the modeled system. When executing plans in the actual system, the model might be inaccurate in a critical point, and plan execution may fail. There are two options to handle this case: the previous solution can be modified to address the failure (plan repair), or the planning process can be re-started from the new situation (re-planning). In HTN planning, discarding the plan and generating a new one from the novel situation is not easily possible, because the HTN solution criteria make it necessary to take already executed actions into account. Therefore all approaches to repair plans in the literature are based on specialized algorithms. In this paper, we discuss the problem in detail and introduce a novel approach that makes it possible to use unchanged, off-the-shelf HTN planning systems to repair broken HTN plans. That way, no specialized solvers are needed.
https://link.springer.com/chapter/10.1007/978-3-030-58285-2_7
Machine Learning
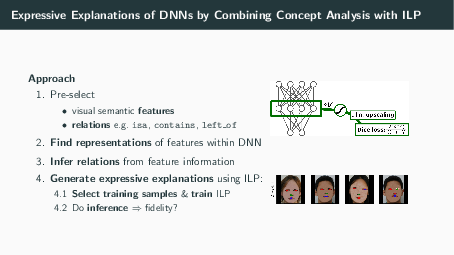
Explainable AI has emerged to be a key component for black-box machine learning approaches in domains with a high demand for reliability or transparency. Examples are medical assistant systems, and applications concerned with the General Data Protection Regulation of the European Union, which features transparency as a cornerstone. Such demands require the ability to audit the rationale behind a classifier’s decision. While visualizations are the de facto standard of explanations, they come short in terms of expressiveness in many ways: They cannot distinguish between different attribute manifestations of visual features (e.g. eye open vs. closed), and they cannot accurately describe the influence of absence of, and relations between features. An alternative would be more expressive symbolic surrogate models. However, these require symbolic inputs, which are not readily available in most computer vision tasks. In this paper we investigate how to overcome this: We use inherent features learned by the network to build a global, expressive, verbal explanation of the rationale of a feed-forward convolutional deep neural network (DNN). The semantics of the features are mined by a concept analysis approach trained on a set of human understandable visual concepts. The explanation is found by an Inductive Logic Programming (ILP) method and presented as first-order rules. We show that our explanation is faithful to the original black-box model (The code for our experiments is available at https://github.com/mc-lovin-mlem/concept-embeddings-and-ilp/tree/ki2020).
https://link.springer.com/chapter/10.1007/978-3-030-58285-2_11
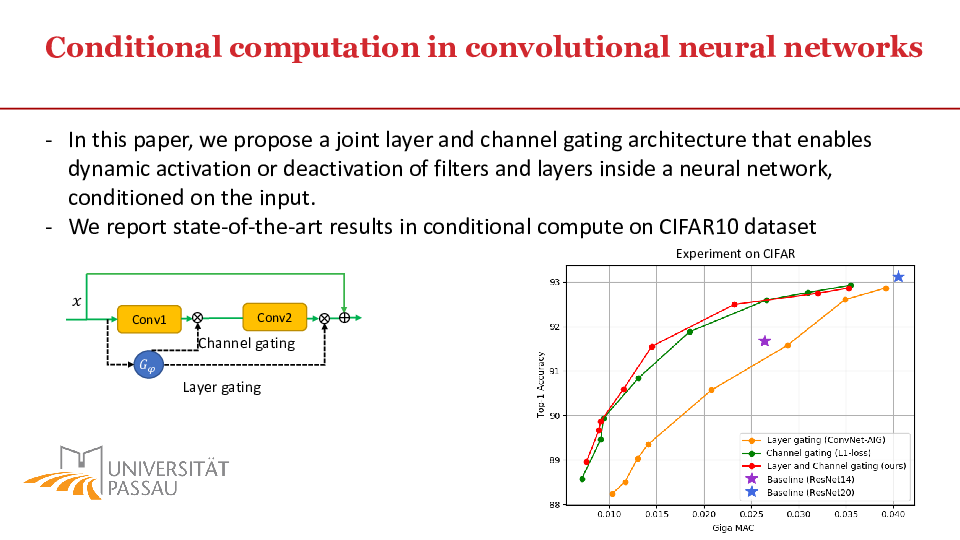
Convolutional neural networks (CNN) are getting more and more complex, needing enormous computing resources and energy. In this paper, we propose methods for conditional computation in the context of image classification that allows a CNN to dynamically use its channels and layers conditioned on the input. To this end, we combine light-weight gating modules that can make binary decisions without causing much computational overhead. We argue, that combining the recently proposed channel gating mechanism with layer gating can significantly reduce the computational cost of large CNNs. Using discrete optimization algorithms, the gating modules are made aware of the context in which they are used and decide whether a particular channel and/or a particular layer will be executed. This results in neural networks that adapt their own topology conditioned on the input image. Experiments using the CIFAR10 and MNIST datasets show how competitive results in image classification with respect to accuracy can be achieved while saving up to 50% computational resources.
https://link.springer.com/chapter/10.1007/978-3-030-58285-2_3

In multiagent organizations, the coordination of problem-solving capabilities builds the foundation for processing complex tasks. Roles provide a structured approach to consolidate task-processing responsibilities. However, designing roles remains a challenge since role configurations affect individual and team performance. On the one hand, roles can be specialized on certain tasks to allow for efficient problem solving. On the other hand, this reduces task processing flexibility in case of disturbances. As agents gain experience knowledge by enacting certain roles, switching roles becomes difficult and requires training. Hence, this paper explores the effects of different role designs on learning agents at runtime. We utilize an adaptive Belief-Desire-Intention agent architecture combined with a reinforcement learning approach to model experience knowledge, task-processing improvement, and decision-making in a stochastic environment. The model is evaluated using an emergency response simulation in which agents manage fire departments for which they configure and control emergency operations. The results show that specialized agents learn to process their assigned tasks more efficient than generalized agents.
https://link.springer.com/chapter/10.1007/978-3-030-58285-2_14
Knowledge Representation and Reasoning

This paper summarizes results on embedding ontologies expressed in the ALC description logic into a real-valued vector space, comprising restricted existential and universal quantifiers, as well as concept negation and concept disjunction. The main result states that an ALC ontology is satisfiable in the classical sense iff it is satisfiable by a partial faithful geometric model based on cones. The line of work to which we contribute aims to integrate knowledge representation techniques and machine learning. The new cone-model of ALC proposed in this work gives rise to conic optimization techniques for machine learning, extending previous approaches by its ability to model full ALC.
This is an extended abstract of the paper “Cone Semantics for Logics with Negation” published in the proceedings of the 29th International Joint Conference on Artificial Intelligence (IJCAI 2020).
https://link.springer.com/chapter/10.1007/978-3-030-58285-2_17

Descriptor revision by Hansson is a framework for addressing the problem of belief change. In descriptor revision, different kinds of change processes are dealt with in a joint framework. Individual change requirements are qualified by specific success conditions expressed by a belief descriptor, and belief descriptors can be combined by logical connectives. This is in contrast to the currently dominating AGM paradigm shaped by Alchourrón, Gärdenfors, and Makinson, where different kinds of changes, like a revision or a contraction, are dealt with separately. In this article, we investigate the realisation of descriptor revision for a conditional logic while restricting descriptors to the conjunction of literal descriptors. We apply the principle of conditional preservation developed by Kern-Isberner to descriptor revision for conditionals, show how descriptor revision for conditionals under these restrictions can be characterised by a constraint satisfaction problem, and implement it using constraint logic programming. Since our conditional logic subsumes propositional logic, our approach also realises descriptor revision for propositional logic.
https://link.springer.com/chapter/10.1007/978-3-030-58285-2_15

Free logics are a family of logics that are free of any existential assumptions. Unlike traditional classical and non-classical logics, they support an elegant modeling of nonexistent objects and partial functions as relevant for a wide range of applications in computer science, philosophy, mathematics, and natural language semantics. While free first-order logic has been addressed in the literature, free higher-order logic has not been studied thoroughly so far. The contribution of this paper includes (i) the development of a notion and definition of free higher-order logic in terms of a positive semantics (partly inspired by Farmer’s partial functions version of Church’s simple type theory), (ii) the provision of a faithful shallow semantical embedding of positive free higher-order logic into classical higher-order logic, (iii) the implementation of this embedding in the Isabelle/HOL proof-assistant, and (iv) the exemplary application of our novel reasoning framework for an automated assessment of Prior’s paradox in positive free quantified propositional logics, i.e., a fragment of positive free higher-order logic.
https://link.springer.com/chapter/10.1007/978-3-030-58285-2_9

A conditional knowledge base R is a set of conditionals of the form “If A then usually B”. Using structural information derived from the conditionals in R, we introduce the preferred structure relation on worlds. The preferred structure relation is the core ingredient of a new inference relation called system W inference that inductively completes the knowledge given explicitly in R. We show that system W exhibits desirable inference properties like satisfying system P and avoiding, in contrast to, e.g., system Z, the drowning problem. It fully captures and strictly extends both system Z and skeptical c-inference. In contrast to skeptical c-inference, it does not require to solve a complex constraint satisfaction problem, but is as tractable as system Z.
https://link.springer.com/chapter/10.1007/978-3-030-58285-2_8

The Weak Completion Semantics is a computational and nonmonotonic cognitive theory based on the three-valued logic of Łukasiewicz. It has been applied to adequately model – among others – the suppression task, the selection task, syllogistic reasoning, and conditional reasoning. In this paper we investigate the case where the antecedent of a conditional is true, but its consequent is unknown. We propose to apply abduction in order to find an explanation for the consequent. This allows to derive new conditionals which are necessarily true. But it also leads to two problems, viz. that consequents should not abduce themselves and that the antecendent of a conditional should be relevant to its consequent. We propose solutions for both problems.
https://link.springer.com/chapter/10.1007/978-3-030-58285-2_6
Applications

The automatic transcription of historical printings with OCR has made great progress in recent years. However, the correct segmentation of demanding page layouts is still challenging, in particular, the separation of text and non-text (e.g. pictures, but also decorated initials). Fully convolutional neural nets (FCNs) with an encoder-decoder structure are currently the method of choice, if suitable training material is available. Since the variation of non-text elements is huge, the good results of FCNs, if training and test material are similar, do not easily transfer to different layouts. We propose an approach based on dividing a page into many contours (i.e. connected components) and classifying each contour with a standard Convolutional neural net (CNN) as being text or non-text. The main idea is that the CNN learns to recognize text contours, i.e. letters, and classifies everything else as non-text, thus generalizing better on the many forms of non-text. Evaluations of the contour-based segmentation in comparison to classical FCNs with varying amount of training material and with similar and dissimilar test data show its effectiveness.
https://link.springer.com/chapter/10.1007/978-3-030-58285-2_4
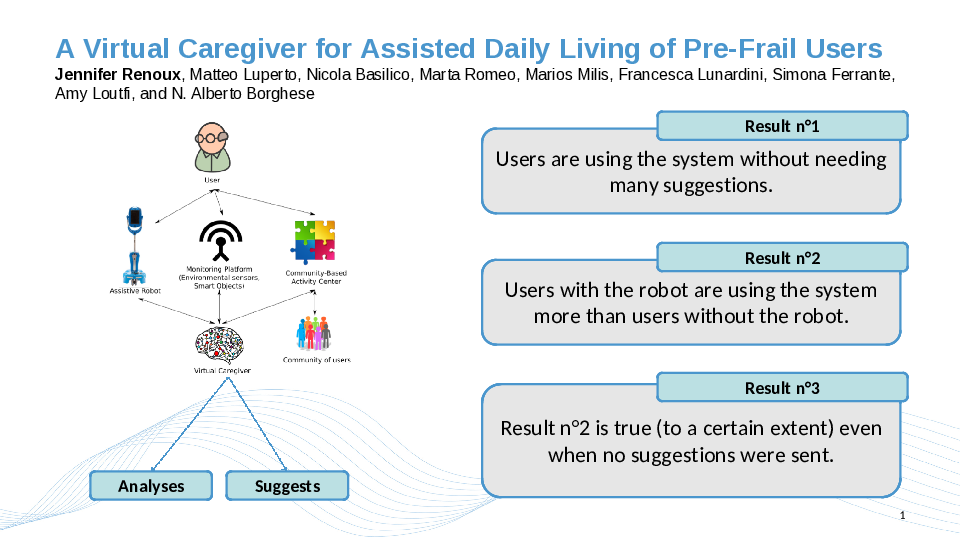
As Europe sees its population aging dramatically, Assisted Daily Living for the elderly becomes a more and more important and relevant research topic. The Movecare Project focuses on this topic by integrating a robotic platform, an IoT system, and an activity center to provide assistance, suggestions of activities and transparent monitoring to users at home. In this paper, we describe the Virtual Caregiver, a software component of the Movecare platform, that is responsible for analyzing the data from the various modules and generating suggestions tailored to the user’s state and needs. A preliminary study has been carried on over 2 months with 15 users. This study suggests that the presence of the Virtual Caregiver encourages people to use the Movecare platform more consistently, which in turn could result in better monitoring and prevention of cognitive and physical decline.
https://link.springer.com/chapter/10.1007/978-3-030-58285-2_13
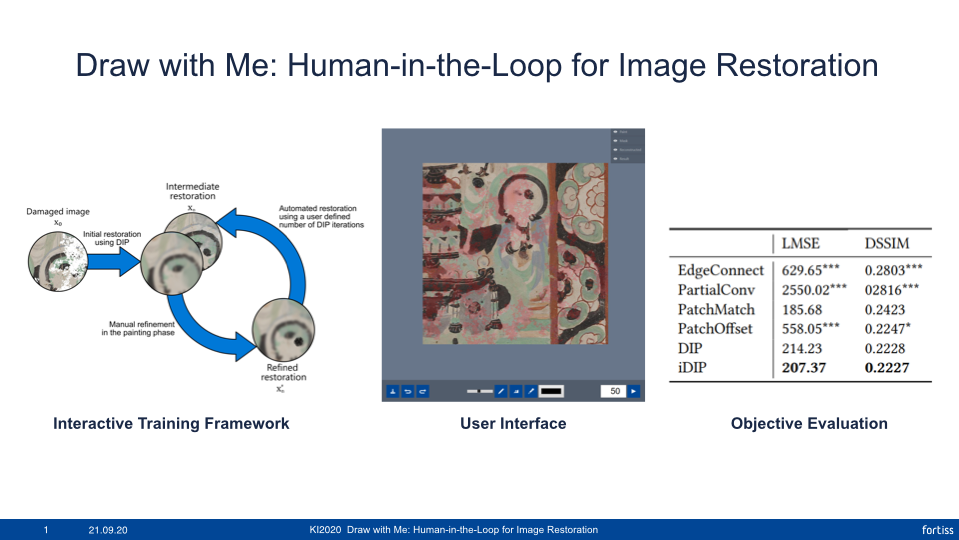
The purpose of image restoration is to recover the original state of damaged images. To mitigate the disadvantages of the manual image restoration process such as the high time consumption, we present interactive Deep Image Prior by extending Deep Image Prior with a user interface to an interactive process with the human in the loop. In this process, a human can iteratively embed knowledge to provide guidance and control for the automated inpainting process.
Our evaluation shows that, even with very little human guidance, our interactive approach has a restoration performance on par or superior to other methods. Meanwhile, very positive results of our user study suggest that learning systems with the human-in-the-loop positively contribute to user satisfaction
The full paper to this contribution is published in:
IUI 2020: Proceedings of the 25th International Conference on Intelligent User Interfaces. Association for Computing Machinery, New York, NY, USA (2020)
https://link.springer.com/chapter/10.1007/978-3-030-58285-2_19
Awards
- Best Paper
-
Low-Rank Subspace Override for Unsupervised Domain Adaptation
- Best Paper Presentation
-
Meta-induction, Probability Aggregation, and Optimal Scoring
- Best Poster Presentation
-
Firefighter Virtual Reality Simulation for Personalized Stress Detection
Supported by



